Caching Header Best Practices
Introduction
Caching headers are one of those deceptively complex web technologies which are so often overlooked or misconfigured. The fastest request is the one that is not made, and caching headers allow us to tell browsers when they can reuse an asset that they have already downloaded. The reason that these headers are often misconfigured, or at least configured suboptimally, is often through a descent to lowest risk. Allowing a browser to use a cached asset can be considered risky - JS which falls out of sync with HTML, CSS which persists an old campaign style, personalised assets accidentally being shared between visitors.
In this post we will review what caching headers are available and when they should be used. We'll also talk about invalidating caches and ensuring browsers use the correct assets at the correct time. Note that the focus of this post is on client-side (or downstream) caching - in the client device. Caching in proxies, load balancers and Content Delivery Networks (CDNs) adds some more complexity, and is not covered here.
The Solution
Use versioned assets wherever possible (e.g. main.v123.min.css or main.min.css?v=123) and set a single caching header allowing the maximum cache duration of one year:
Cache-Control: max-age=31536000, immutableFor non-versioned assets which may change, combine the Cache-Control header with an ETag for asynchronous revalidation in the client:
Cache-Control: max-age=604800, stale-while-revalidate=86400
ETag: "<file-hash-generated-by-server>"For HTML files, set a low TTL and private cache flags:
Cache-Control: max-age:300, privateDo not emit unnecessary caching headers (including ETag and Last-Modified) to prevent unexpected client and server behaviours.

Caching Headers
There are a number of response headers set by a web server or CDN which manage client-side caching. Some are more obvious than others!
Expires - a date (in GMT) after which this asset may no longer be used from the browsers cache and must be re-fetched (docs)
Cache-Control - a combination of features in one header, including how long the resource can be cached by the client (in seconds) as well as whether proxies can cache it, whether to force revalidation and more (docs)
ETag - a string that uniquely identifies an asset version, generally a server-generated hash of the file (docs)
Last-Modified - a timestamp which allows browsers to validate the freshness of cached assets (docs)
Pragma - a hangover from HTTP/1.0, this should generally not be used in preference for Cache-Control except where HTTP/1.0 clients must be supported (docs)
In general I recommend to not emit an Expires header and rely instead on the more comprehensive Cache-Control header. I also recommend to not emit a Last-Modified header and use ETag instead for asset revalidation, this avoids edge cases such as newer files with identical content or clock mismatches between web servers which would cause unnecessary bandwidth consumption.
For revalidation (aka conditional requests) to work, responses must be served with one or both of the ETag or Last-Modified headers. The server must also understand conditional get requests and respond with a 304 Not Modified in the case that the cached asset matches that on origin. Note that validation of weak ETags (prefixed by W/ in the header) are unsupported in some scenarios — including if using Akamai as a CDN — so you may want to use strong ETags where possible.
ETags are simply strings which identify a specific version of an asset. Weak ETags (prefixed with
W/) should match assets which are semantically the same (e.g. metadata has been updated but the content is the same), whereas strong ETags should change whenever the asset is changed in any way. (See RFC 7232 for more info!)By default, Apache 2.3.14 and earlier included
INodein the ETag - meaning that the ETag for an identical asset would change between servers! This is no longer included by default, and you can configure what is used to produce the ETag in Apache. The default is to use the last-modified time and the file size, but you can also choose to use a file digest, and manually include the INode back into the calculation.If you have your own versioning implemented on the web server you could generate ETags yourself. E.g.
ETag: core-js-es6-v13.1234-gzip. But then you might as well rename the file to break the cache on the front-end.
Caching Behaviours
There are generally four types of caching behaviour we may want a browser to use when it has downloaded a static asset:
1. Not Cacheable
For assets that are dynamically generated, that are unique or that are only valid once.
Cache-Control: no-cache
This directive tells the client that it can cache the asset, but it cannot use the cached asset without revalidating with the server. If the asset cannot be revalidated (i.e. there were no ETag or Last-Modified response headers on the asset) then the cached asset will never be used.
Cache-Control: no-store
This directive tells the client that the asset may not be stored in cache at all. Any further requests for this asset will be full requests back to the server.
2. Immutable
These assets that can be stored by the browser indefinitely because they never change. Use this for versioned assets (e.g. main.v123.min.css or main.min.css?v=123).
Cache-Control: max-age=31536000, immutableThe immutable directive explicitly tells the browser (where supported) that the asset can be stored for a year and never needs to be revalidated.
3. Time-restricted
For assets which should be stored for the duration of a session (e.g. one day or one week) but should be refreshed or revalidated if the visitor returns later.
Cache-Control: max-age=864004. Revalidated
When combined with #3, this allows browsers to use a cached asset for a period of time (from zero seconds up to a year) and then revalidate the object with origin once that period has expired. stale-while-revalidate causes the revalidation request to happen asynchronously, improving performance at the potential risk of using stale content with a second time to live (TTL) value for how long the stale asset may be used.
Cache-Control: max-age=604800, stale-while-revalidate=86400Optimal Caching Strategy
In general we want browsers to cache everything forever. This can be achieved quite simply by setting a Cache-Control: max-age=31536000 response header - using the maximum TTL value of one year. The issue is that your web applications likely change more frequently than yearly. This is where the most important feature of your web build pipeline comes in - versioned assets!
With versioned assets, the browser will automatically ignore stale cached assets as the references will be updated. Instead of the HTML document requesting main.v123.min.css, the reference will be to main.v124.min.css (note the incremented version number, this will be automatically generated at build time and may be an asset hash).
If assets will always be versioned, we can consider them immutable. That means that if the content of the file changes we guarantee that the filename is changed. Some browsers support this concept natively in the cache-control header, preventing revalidation requests ever being made for these assets:
Cache-Control: max-age=31536000, immutableQuery Strings and Caching
If an asset filename cannot be updated automatically, a query string parameter can be added to the URL to break the cache. For example main.min.css?v=124. This method should be robust in most cases, ensuring that your CDN configuration treats query strings as part of the asset cache key for caching at the CDN level:
- Cloudflare includes query strings by default
- Akamai excludes query strings by default
- Fastly includes query strings by default
Irregular Updates to Unversioned Assets
One of the trickiest caching scenarios to manage is where an asset is unversioned (no unique identifier in the URL) and it is updated on an irregular schedule. This could be, for example, a document containing stock information, transport schedules or feature flags.
In this case, we still want the browser to be able to use the cached asset but also ensure that it remains relatively fresh. This is (in my opinion) the only scenario where entity tags (ETags) make sense. ETags should be used in combination with a valid Cache-Control header to ensure you have control over how the browser manages its cache state:
Cache-Control: max-age=86400, must-revalidate
ETag: "a-unique-hash-generated-by-the-server"This example will allow the browser to use the cached asset for up to 24 hours (86,400 seconds), after which it must revalidate with the server. A revalidation request (also known as a conditional GET request) acts just like a normal request for the asset, with the addition of one or two request headers: If-None-Match where an ETag was present on the original response, If-Modified-Since in the case that a Last-Modified header was present:
GET /main.min.css
Accept: */*
Accept-Encoding: gzip,br
If-None-Match: "a-unique-hash-generated-by-the-server"This If-None-Match header is a message to the server that the client has a version of the asset in cache. The server can then check to see whether this is still a valid version of the asset - if so, we will receive an empty 304 response with another ETag which will match the original:
304 Not Modified
ETag: "a-unique-hash-generated-by-the-server"If the asset has changed since the client cached it, we will get a full response with the new ETag:
200 Found
Content-Length: 100000
ETag: "a-NEW-unique-hash-generated-by-the-server"This approach is valuable, but does have drawbacks:
- Generating & maintaining asset hashes has a small compute cost on the server
- Some web servers have bugs with ETag generation and validation, especially with multiple servers behind a load balancer
- A
304response will add a small front-end delay for each request and incurs a small amount of compute on the web server - the client will not use the (valid) cached asset until the304response is received
A similar process occurs when the Last-Modified header is present on responses. You may see conditional requests sent with the If-Modified-Since header:
GET /main.min.css
If-Modified-Since: Wed, 21 Oct 2015 07:28:00 GMTIf both If-Modified-Since and If-None-Match request headers are present then the server must only return a 304 if both conditional fields match the origin content. The If-Modified-Since header allows the server to check the last modified time of the requested asset and again return a 304 Not Modified if it is the equal to or earlier than the timestamp in the request.
Using Last-Modified may cause more cache-misses than ETag if releases touch all files on the web server, even if they have no updates (updating the last modified time on all files). There is a benefit to using Last-Modified over ETag in the edge case where servers may hold older versions of an asset - the ETag will not match and result in a full 200 response, whereas the Last-Modified date will be later than the origin asset, resulting in an empty 304 response.
What about HTML?
HTML assets are critical to performance in traditional (non-SPA) web applications. A 100ms delay downloading the HTML for a page will make everything else 100ms slower.
Folks are normally very nervous about allowing browsers to cache HTML though, for a number of good reasons:
- Personalisation in the page (e.g. user name, basket contents, geolocation logic)
- Asset versions (e.g.
main.v123.min.css) are updated in the HTML to purge the client cache on release - Rapid updates (e.g. a news publication with breaking stories)
Even with all of these considerations, caching HTML can still be achieved and performance can be significantly improved. We just need to be careful!
Short TTLs & private caches
Allowing an HTML asset to be cached for a short period can improve user experience with minimal risk. Setting a TTL of five minutes (300s) for example should be fine, you can also add must-revalidate to ensure that browsers do not use a stale version of the asset after the TTL has expired. This will benefit visitors who click links returning them to previously visited pages, this does not affect the back/forward cache.
The Cache-Control header offers the private attribute, indicating that assets should not be stored by any proxies or CDNs, but may be cached by the client. This attribute enables you to allow browsers to cache personalised content - as the cached asset will not be shared across multiple visitors.
Remove dynamic elements from the HTML document
Dynamic elements such as a basket count, user name, logged in / out status indicator all make caching HTML more tricky. Externalising these out to API calls, JavaScript and localStorage will mean that the base HTML template can be cached in the browser, with dynamic elements updated as the page is building. This will also allow pages to be cached by CDNs - greatly reducing Time to First Byte (TTFB) and thus improving experience.
This concept can be taken further in some scenarios, such as when anonymous visitors are presented generic / un-personalised pages. In this case, you can detect the anonymous visitor (e.g. by presence of a user cookie) and serve them a cached page from the CDN, whereas logged-in / recognised visitors will be served by origin to allow personalisation code to run. The possibilities here are quite exciting!
General Recommendations
Explicitly set the Cache-Control header on all responses. Do not set the following response headers in most scenarios:
Last-ModifiedExpiresETagPragma
Always set the Cache-Control header, preferably with the value max-age=31536000,immutable alongside unique asset filenames (or no-cache for non-cacheable assets).
In some scenarios, use ETags to allow browsers to revalidated cached content using the following headers (e.g. cache for one week, allow stale assets with async revalidation for up to one day after cache expiry):
Cache-Control: max-age=604800,stale-while-revalidate=86400
ETag: "<generated-by-server>"The lack of Last-Modified and ETag headers on a response prevents the browser from making conditional GET requests, potentially reducing back-end load.
Ensure that your web application server / load-balancer / CDN handles conditional GET requests correctly and returns a 304 Not Modified response when ETags match. Use cURL or redbot.org to test this.
How to check your headers
Throughout this post I have detailed headers that you might see when requesting assets - of course these aren't visible on the web application directly! There are two key methods to check the response headers of your assets: using the browser and using command-line tools.
Browser developer tools
All browsers have developer tools to help analyse network traffic, in Google Chrome you can press ⌘ + ⌥ + i ( ctrl + shift + i on Windows) to bring up Chrome Developer Tools, it will default to the last open tab so you may need to select the network tab. The network tab only records traffic whilst open, so reload the page to view the requests if none are present.
Once you have some traffic, click on a request to see more details:

If this is a task that you will repeat often, I recommend adding the relevant response headers to the network table. Right-click on the column headers and select Response Headers, Cache-Control should be there by default and you can also add custom headers here.
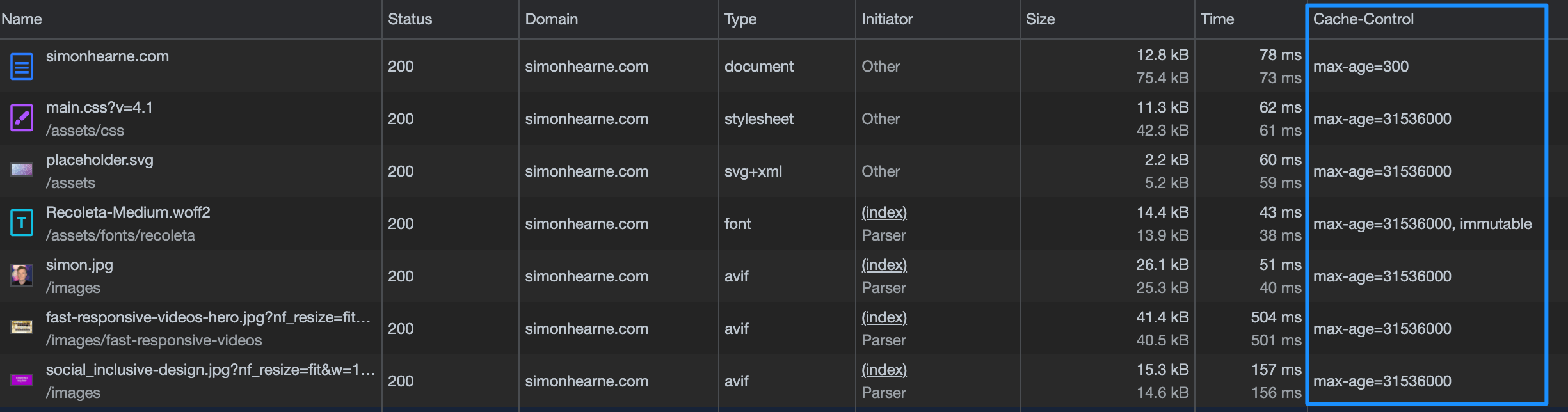
Command-line tools
cURL is one of the most widely deployed command line tools and is ideal for checking response headers. A simple command such as curl 'https://simonhearne.com/css/main.css?v=4.1' -Is will show you all response headers for the object, although we can build on this to focus just on the headers that we care about for caching (note that I have added some required request headers user-agent and accept-language so that a valid response is provided):
curl 'https://phoenixnap.com/kb/wp-includes/css/dist/block-library/style.min.css?ver=5.9' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36' \
-H 'accept-language: en-GB,en-US;q=0.9,en;q=0.8' \
--compressed -Is | grep -E 'cache-control|etag|last-modified|expires|pragma'
last-modified: Wed, 26 Jan 2022 05:24:24 GMT
etag: W/"61f0db08-1357b"
expires: Thu, 26 Jan 2023 11:29:02 GMT
cache-control: max-age=31536000
pragma: public
cache-control: max-age=31536000, publicFor this example, I would recommend that the website owner investigates the various response headers here which may conflict with each other. This set of six response headers could be replaced with a single header: Cache-Control: max-age=31536000! Redbot also shows a number of warnings for this implementation:
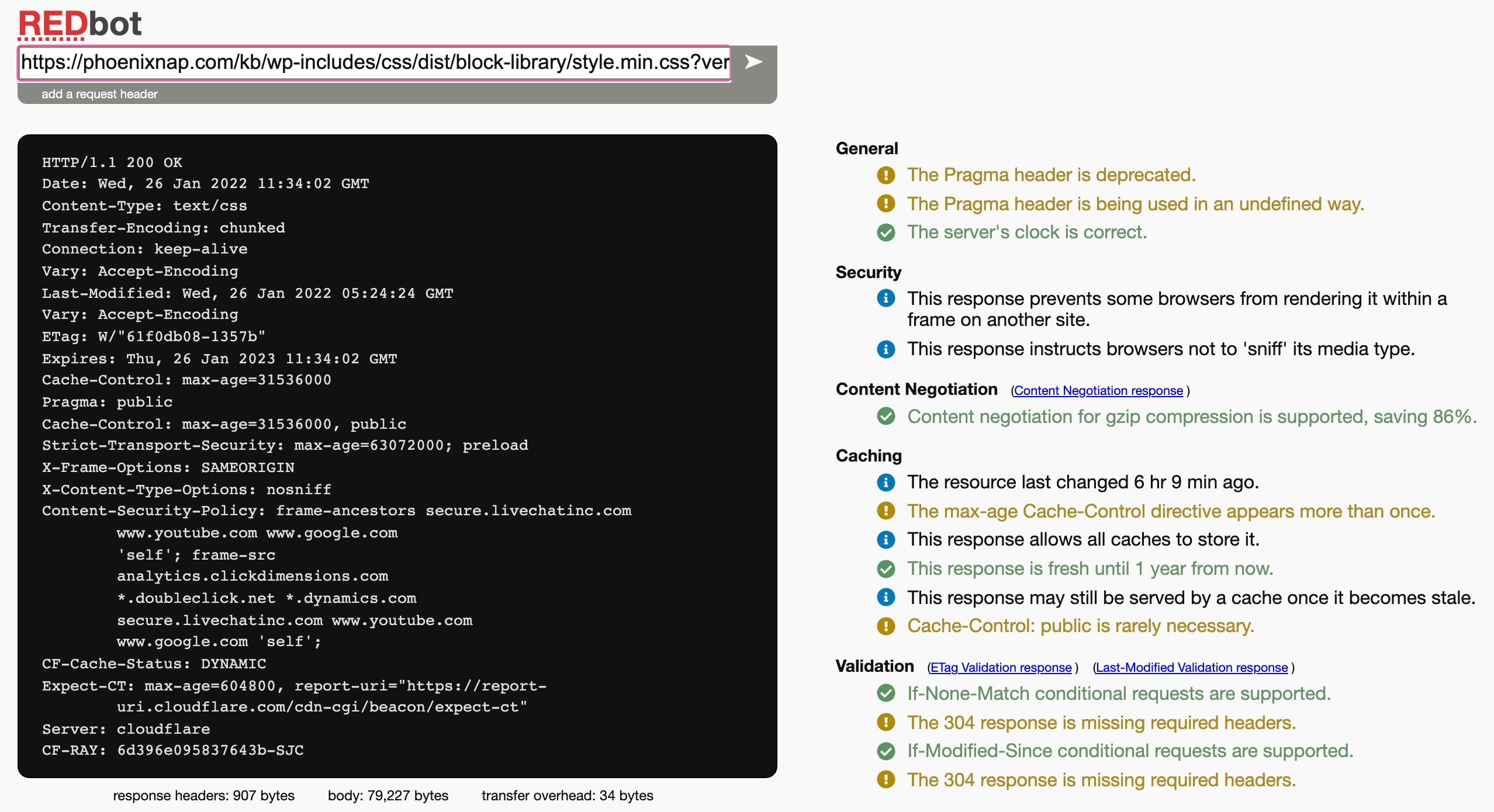
How to change response headers
Once you have determined your caching header strategy and reviewed the headers that are currently being emitted - it's time to make some changes!
Response headers can be set at multiple stages depending on your application architecture - for example the web server, load balancer and CDN can all set and modify response headers. Generally we should expect response headers to be forwarded transparently through proxies such as load balancers and CDNs unless explicit changes have been made, so the web server is the best place to start. You should be able to find what you need with a search for <web server name> set response headers or <web server name> set caching headers on your search engine of choice. For convenience, here are the relevant docs pages for some major web servers, PaaS / SaaS and CDN solutions:
Web Servers
PaaS / SaaS
- Netlify - note that there is an open issue regarding setting headers by content-type.
- Wix - note that Wix does not provide fine-grained control over caching headers
- WPengine
- Webflow - it doesn't look like you can control headers and the recommendation is to use a CDN in front of Webflow
CDNs
- Akamai
- Fastly
- Cloudflare - lets you set a TTL but no fine-grained control over response headers
- Cloudflare Pages
- Cloudflare Workers - I use a worker in front of Netlify to overcome limitations in netlify.toml. Provides absolute control over response headers.
A note on Cache-Control: public
A lot of resources (e.g. on web.dev) recommend setting the public attribute on Cache-Control headers if resources can be shared between visitors. This is potentially misleading as public is the default behaviour where private is not set.
The public attribute should not be set in almost all cases, as it can lead to an issue with authorized requests. Setting the public attribute in a Cache-Control header for an authorized request (i.e. one which is made with an Authorization header) will explicitly allow intermediary servers to store and serve the response to other visitors. In most cases this is not the expected behaviour and could lead to data leakage.
In closing…
Client-side caching is a key technique to improving front-end speed and user experience. Whilst it may appear complex and risky, investing the time to review your content and setting the correct response headers will reduce bandwidth utilisation and improve speed for return visitors as well as mid-session.
There are multiple methods to manage caching, in this article I have presented a preference for Cache-Control (and ETag where appropriate). Exact implementation is not as important as correctness and consistency, though. Use what works for your application architecture, environment and processes.